Deep Learning (LeCun, Bengio & Hinton — Nature 2015) (ฉบับแปลไทย)
คำแปลไทยฉบับละเอียดของบทความรีวิวคลาสสิก “Deep Learning” โดย Yann LeCun, Yoshua Bengio และ Geoffrey Hinton ตีพิมพ์ในวารสาร Nature เล่ม 521 ปี 2015 จัดเรียงตามหัวข้อต้นฉบับ พร้อมคงศัพท์เทคนิคภาษาอังกฤษไว้ในวงเล็บเพื่อการอ้างอิง
บทคัดย่อ (Abstract)
การเรียนรู้เชิงลึก (deep learning) ช่วยให้แบบจำลองเชิงคำนวณ (computational models) ที่ประกอบด้วย ชั้นการประมวลผลหลายชั้น (multiple processing layers) สามารถเรียนรู้ การแทนค่าของข้อมูล (representations of data) ที่มีระดับการนามธรรม (abstraction) หลายระดับ ได้ วิธีการเหล่านี้ได้ยกระดับเทคโนโลยีล้ำสมัย (state-of-the-art) อย่างก้าวกระโดดในงานหลายด้าน เช่น การรู้จำเสียงพูด (speech recognition), การรู้จำวัตถุจากภาพ (visual object recognition), การตรวจจับวัตถุ (object detection) รวมถึงโดเมนอื่น ๆ อย่างการค้นพบยา (drug discovery) และจีโนมิกส์ (genomics)
การเรียนรู้เชิงลึกค้นพบโครงสร้างที่ซับซ้อน (intricate structure) ในชุดข้อมูลขนาดใหญ่ โดยใช้ อัลกอริทึมการแพร่ย้อนกลับ (backpropagation algorithm) เพื่อบ่งชี้ว่าเครื่อง (machine) ควรเปลี่ยนแปลง พารามิเตอร์ภายใน (internal parameters) ของตัวเองอย่างไร พารามิเตอร์เหล่านี้ใช้คำนวณการแทนค่าในแต่ละชั้นจากการแทนค่าของชั้นก่อนหน้า
- โครงข่ายคอนโวลูชันเชิงลึก (deep convolutional nets) สร้างความก้าวหน้าครั้งใหญ่ในการประมวลผลภาพ วิดีโอ เสียงพูด และเสียง
- โครงข่ายเวียนซ้ำ (recurrent nets) เปล่งประกายในการจัดการ ข้อมูลเชิงลำดับ (sequential data) เช่น ข้อความและเสียงพูด
บทนำ (Introduction)
เทคโนโลยีการเรียนรู้ของเครื่อง (machine learning) ขับเคลื่อนหลายแง่มุมของสังคมสมัยใหม่ ตั้งแต่การค้นหาบนเว็บ การกรองเนื้อหาบนโซเชียลเน็ตเวิร์ก ไปจนถึงระบบแนะนำสินค้า (recommendations) บนเว็บอีคอมเมิร์ซ และปรากฏมากขึ้นในสินค้าอุปโภคบริโภค เช่น กล้องและสมาร์ตโฟน ระบบ machine learning ถูกใช้ระบุวัตถุในภาพ ถอดเสียงพูดเป็นข้อความ จับคู่ข่าว/โพสต์/สินค้าให้ตรงกับความสนใจของผู้ใช้ และคัดเลือกผลการค้นหาที่เกี่ยวข้อง โดยแอปพลิเคชันเหล่านี้ใช้เทคนิคกลุ่มหนึ่งที่เรียกว่า deep learning มากขึ้นเรื่อย ๆ
ข้อจำกัดของ machine learning แบบดั้งเดิม
เทคนิค machine learning แบบดั้งเดิม มีข้อจำกัดในการประมวลผลข้อมูลธรรมชาติในรูปดิบ (raw form) เป็นเวลาหลายทศวรรษ การสร้างระบบรู้จำรูปแบบ (pattern recognition) ต้องอาศัย วิศวกรรมที่พิถีพิถันและความเชี่ยวชาญเฉพาะโดเมน (domain expertise) อย่างมาก เพื่อออกแบบ ตัวสกัดคุณลักษณะ (feature extractor) ที่แปลงข้อมูลดิบ (เช่น ค่าพิกเซลของภาพ) ให้เป็น การแทนค่าภายใน (internal representation) หรือ เวกเตอร์คุณลักษณะ (feature vector) ที่เหมาะสม เพื่อให้ระบบย่อยที่ทำหน้าที่เรียนรู้ (มักเป็นตัวจำแนก/classifier) ตรวจจับหรือจำแนกรูปแบบในอินพุตได้
การเรียนรู้การแทนค่า (Representation Learning)
Representation learning คือชุดวิธีการที่ยอมให้ป้อนข้อมูลดิบเข้าเครื่องได้โดยตรง แล้วเครื่อง ค้นพบการแทนค่าที่จำเป็นสำหรับการตรวจจับ/จำแนกได้เองโดยอัตโนมัติ
Deep learning เป็น representation learning ที่มีการแทนค่าหลายระดับ ได้มาจากการประกอบ (composing) โมดูลที่เรียบง่ายแต่ ไม่เชิงเส้น (non-linear) เข้าด้วยกัน โดยแต่ละโมดูลแปลงการแทนค่าจากระดับหนึ่ง (เริ่มจากอินพุตดิบ) ไปสู่การแทนค่าในระดับที่สูงขึ้นและเป็นนามธรรมมากขึ้นเล็กน้อย เมื่อประกอบการแปลงพอประมาณเข้าด้วยกัน จะเรียนรู้ ฟังก์ชันที่ซับซ้อนมาก (very complex functions) ได้ สำหรับงานจำแนก (classification) ชั้นที่สูงขึ้นจะ ขยาย (amplify) แง่มุมของอินพุตที่สำคัญต่อการแยกแยะ และ กด (suppress) ความผันแปรที่ไม่เกี่ยวข้อง
ตัวอย่างลำดับชั้นในภาพ
ภาพมาในรูป อาเรย์ของค่าพิกเซล (array of pixel values) การเรียนรู้คุณลักษณะแต่ละชั้นโดยทั่วไปเป็นดังนี้:
| ชั้น | สิ่งที่เรียนรู้ตรวจจับ |
|---|---|
| ชั้นที่ 1 | การมี/ไม่มี ขอบ (edges) ที่ทิศทางและตำแหน่งจำเพาะในภาพ |
| ชั้นที่ 2 | ลวดลาย (motifs) จากการจัดเรียงขอบบางแบบ โดยไม่สนใจความผันแปรเล็กน้อยของตำแหน่งขอบ |
| ชั้นที่ 3 | ประกอบ motifs เป็นชุดใหญ่ขึ้นที่ตรงกับ ส่วนของวัตถุที่คุ้นเคย (parts of objects) |
| ชั้นถัด ๆ ไป | ตรวจจับ วัตถุ (objects) ในฐานะการรวมกันของส่วนเหล่านั้น |
หัวใจสำคัญ: ชั้นของคุณลักษณะ (layers of features) เหล่านี้ ไม่ได้ถูกออกแบบโดยวิศวกรมนุษย์ แต่ เรียนรู้จากข้อมูลด้วยกระบวนการเรียนรู้เอนกประสงค์ (general-purpose learning procedure)
ความสำเร็จของ deep learning
Deep learning ทำให้เกิดความก้าวหน้าครั้งใหญ่ในการแก้ปัญหาที่ท้าทายวงการ AI มานานหลายปี มันเก่งมากในการค้นพบโครงสร้างที่ซับซ้อนในข้อมูล มิติสูง (high-dimensional data) จึงประยุกต์ใช้ได้ทั้งในวิทยาศาสตร์ ธุรกิจ และภาครัฐ นอกจากทำลายสถิติด้านการรู้จำภาพและเสียงพูดแล้ว ยังเอาชนะเทคนิคอื่นในการ:
- ทำนายฤทธิ์ของโมเลกุลยา (drug molecules)
- วิเคราะห์ข้อมูลเครื่องเร่งอนุภาค (particle accelerator)
- สร้างวงจรสมองขึ้นใหม่ (reconstructing brain circuits)
- ทำนายผลของการกลายพันธุ์ใน DNA ที่ไม่เข้ารหัส (non-coding DNA) ต่อการแสดงออกของยีนและโรค
- งานความเข้าใจภาษาธรรมชาติ (NLU) เช่น การจัดหมวดหัวข้อ, การวิเคราะห์อารมณ์ (sentiment analysis), การตอบคำถาม (question answering), การแปลภาษา (translation)
ผู้เขียนเชื่อว่า deep learning จะประสบความสำเร็จมากขึ้นในอนาคตอันใกล้ เพราะ ใช้วิศวกรรมด้วยมือ (engineering by hand) น้อยมาก จึงใช้ประโยชน์จากการเพิ่มขึ้นของพลังการคำนวณและปริมาณข้อมูลได้ง่าย
การเรียนรู้แบบมีผู้สอน (Supervised Learning)
รูปแบบที่พบบ่อยที่สุดของ machine learning (ไม่ว่าจะลึกหรือไม่) คือ การเรียนรู้แบบมีผู้สอน (supervised learning)
ขั้นตอนการทำงาน
ลองนึกภาพว่าเราต้องการสร้างระบบจำแนกภาพว่ามี บ้าน รถ คน หรือสัตว์เลี้ยง
- เก็บชุดข้อมูล (data set) ภาพจำนวนมาก แต่ละภาพ ติดป้ายกำกับหมวด (labelled with category)
- ระหว่างฝึก (training) เครื่องรับภาพ แล้วให้ผลลัพธ์เป็น เวกเตอร์ของคะแนน (vector of scores) หนึ่งค่าต่อหนึ่งหมวด
- เราต้องการให้หมวดที่ถูกต้องมีคะแนนสูงสุด แต่ก่อนฝึกมักไม่เป็นเช่นนั้น
- คำนวณ ฟังก์ชันวัตถุประสงค์ (objective function) ที่วัด ความผิดพลาด (error / distance) ระหว่างคะแนนที่ได้กับรูปแบบคะแนนที่ต้องการ
- เครื่องปรับ พารามิเตอร์ภายในที่ปรับได้ (adjustable parameters) เพื่อลด error นี้
พารามิเตอร์ที่ปรับได้นี้มักเรียกว่า น้ำหนัก (weights) เป็นจำนวนจริง เปรียบเสมือน “ปุ่มหมุน (knobs)” ที่กำหนดฟังก์ชันอินพุต–เอาต์พุตของเครื่อง ระบบ deep learning ทั่วไปอาจมี น้ำหนักหลายร้อยล้านตัว และ ตัวอย่างที่ติดป้ายหลายร้อยล้านตัว
เวกเตอร์เกรเดียนต์ (Gradient Vector)
เพื่อปรับเวกเตอร์น้ำหนักอย่างถูกต้อง อัลกอริทึมจะคำนวณ เวกเตอร์เกรเดียนต์ (gradient vector) ที่บอกว่า — สำหรับน้ำหนักแต่ละตัว — error จะ เพิ่มหรือลด เท่าใด หากเพิ่มน้ำหนักนั้นทีละนิด จากนั้นปรับเวกเตอร์น้ำหนักไปใน ทิศทางตรงข้าม กับเวกเตอร์เกรเดียนต์
Stochastic Gradient Descent (SGD)
ฟังก์ชันวัตถุประสงค์ที่เฉลี่ยทั่วทุกตัวอย่างฝึก เปรียบได้กับ ภูมิประเทศเป็นเนินเขา (hilly landscape) ในปริภูมิมิติสูงของค่าน้ำหนัก เวกเตอร์เกรเดียนต์เชิงลบ (negative gradient) ชี้ทิศทาง ลงชันที่สุด (steepest descent) พาเข้าใกล้จุดต่ำสุด (minimum) ที่ error เฉลี่ยต่ำ
ในทางปฏิบัติ นักวิจัยส่วนใหญ่ใช้กระบวนการ Stochastic Gradient Descent (SGD):
- แสดงเวกเตอร์อินพุตของตัวอย่างไม่กี่ตัว
- คำนวณเอาต์พุตและ error
- คำนวณ เกรเดียนต์เฉลี่ย ของตัวอย่างชุดเล็กนั้น
- ปรับน้ำหนักตามนั้น
- ทำซ้ำกับชุดตัวอย่างเล็ก ๆ จากชุดฝึก จนกว่าค่าเฉลี่ยของ objective function หยุดลดลง
เรียกว่า “stochastic” เพราะแต่ละชุดเล็กให้ ค่าประมาณเกรเดียนต์เฉลี่ยที่มีสัญญาณรบกวน (noisy estimate) กระบวนการเรียบง่ายนี้มักหาชุดน้ำหนักที่ดีได้รวดเร็วอย่างน่าประหลาดใจ เมื่อเทียบกับเทคนิคออปติไมเซชันที่ซับซ้อนกว่ามาก
ชุดทดสอบ (Test Set) และการวางนัยทั่วไป
หลังฝึก ประสิทธิภาพวัดด้วย ชุดทดสอบ (test set) ที่ต่างจากชุดฝึก เพื่อทดสอบ ความสามารถในการวางนัยทั่วไป (generalization ability) — คือความสามารถในการให้คำตอบที่สมเหตุสมผลกับอินพุตใหม่ที่ไม่เคยเห็นระหว่างฝึก
ข้อจำกัดของตัวจำแนกเชิงเส้น (Linear Classifier)
แอปพลิเคชัน machine learning จำนวนมากใช้ ตัวจำแนกเชิงเส้น (linear classifier) บนคุณลักษณะที่ออกแบบด้วยมือ ตัวจำแนกเชิงเส้นสองคลาสคำนวณ ผลรวมถ่วงน้ำหนัก (weighted sum) ขององค์ประกอบเวกเตอร์คุณลักษณะ ถ้าผลรวมเกินเกณฑ์ (threshold) ก็จัดอินพุตเข้าหมวดนั้น
ตั้งแต่ทศวรรษ 1960 เรารู้ว่าตัวจำแนกเชิงเส้นแบ่งปริภูมิอินพุตได้เพียง ภูมิภาคง่าย ๆ คือ ครึ่งปริภูมิ (half-spaces) ที่คั่นด้วย ไฮเปอร์เพลน (hyperplane) แต่ปัญหาอย่างการรู้จำภาพและเสียงต้องการให้ฟังก์ชันอินพุต–เอาต์พุต:
- ไม่ไวต่อ (insensitive) ความผันแปรที่ไม่เกี่ยวข้อง เช่น ตำแหน่ง ทิศทาง แสง หรือระดับเสียง/สำเนียง
- แต่ ไวมาก (very sensitive) ต่อความแตกต่างเล็กน้อยที่สำคัญ
ปัญหา Selectivity–Invariance
ตัวจำแนกแบบตื้นต้องการ feature extractor ที่ดีเพื่อแก้ ปัญหา selectivity–invariance dilemma:
- Selective (เลือกเฟ้น): ไวต่อแง่มุมของภาพที่สำคัญต่อการแยกแยะ
- Invariant (ไม่แปรผัน): ทนทานต่อแง่มุมที่ไม่เกี่ยวข้อง เช่น ท่าทางของสัตว์
อาจใช้คุณลักษณะไม่เชิงเส้นแบบทั่วไป (generic non-linear features) เช่น kernel methods (เคอร์เนลแบบเกาส์เซียน) แต่คุณลักษณะทั่วไปเหล่านี้ ไม่ช่วยให้วางนัยทั่วไปได้ดีในจุดที่ไกลจากตัวอย่างฝึก ทางเลือกดั้งเดิมคือออกแบบ feature extractor ด้วยมือซึ่งใช้ทักษะสูง แต่ทั้งหมดนี้ หลีกเลี่ยงได้ ถ้าเรียนรู้คุณลักษณะที่ดีได้อัตโนมัติด้วยกระบวนการเรียนรู้เอนกประสงค์ — นี่คือข้อได้เปรียบหลักของ deep learning
สถาปัตยกรรม deep learning
สถาปัตยกรรม deep learning คือ สแต็กหลายชั้นของโมดูลเรียบง่าย (multilayer stack of simple modules) ซึ่งส่วนใหญ่อยู่ภายใต้การเรียนรู้ และหลายโมดูลคำนวณการแมปอินพุต–เอาต์พุตแบบไม่เชิงเส้น แต่ละโมดูลเพิ่มทั้ง selectivity และ invariance ของการแทนค่า ด้วยชั้นไม่เชิงเส้นหลายชั้น (เช่น ลึก 5 ถึง 20 ชั้น) ระบบสามารถสร้างฟังก์ชันที่ซับซ้อนยิ่งยวด ซึ่งไวต่อรายละเอียดเล็กน้อย (แยก Samoyed กับหมาป่าขาว) และไม่ไวต่อความผันแปรใหญ่ที่ไม่เกี่ยวข้อง (พื้นหลัง ท่าทาง แสง วัตถุรอบข้าง) พร้อมกัน
Backpropagation สำหรับฝึกสถาปัตยกรรมหลายชั้น
ตั้งแต่ยุคแรกของ pattern recognition เป้าหมายของนักวิจัยคือ แทนที่คุณลักษณะที่ออกแบบด้วยมือ ด้วยโครงข่ายหลายชั้นที่ฝึกได้ (trainable multilayer networks) แต่แม้วิธีนี้จะเรียบง่าย กลับไม่เป็นที่เข้าใจกว้างขวางจนถึง กลางทศวรรษ 1980 ปรากฏว่าสถาปัตยกรรมหลายชั้นสามารถฝึกด้วย SGD ธรรมดาได้ ตราบใดที่โมดูลเป็นฟังก์ชันที่ค่อนข้างเรียบ (smooth) ของอินพุตและน้ำหนักภายใน เราคำนวณเกรเดียนต์ได้ด้วย กระบวนการ backpropagation แนวคิดนี้ถูกค้นพบโดยอิสระจากหลายกลุ่มในช่วงทศวรรษ 1970–1980
หลักการของ Backpropagation
Backpropagation สำหรับคำนวณเกรเดียนต์ของ objective function เทียบกับน้ำหนัก ก็คือการประยุกต์ใช้กฎลูกโซ่ของอนุพันธ์ (chain rule for derivatives) เท่านั้นเอง
Key insight: อนุพันธ์ (เกรเดียนต์) ของ objective เทียบกับ อินพุตของโมดูล คำนวณได้โดย ทำงานย้อนกลับ (working backwards) จากเกรเดียนต์เทียบกับ เอาต์พุตของโมดูลนั้น (หรืออินพุตของโมดูลถัดไป) สมการ backpropagation ถูกใช้ซ้ำ ๆ เพื่อแพร่เกรเดียนต์ผ่านทุกโมดูล เริ่มจากเอาต์พุตด้านบน (ที่โครงข่ายให้คำทำนาย) ไปจนถึงด้านล่าง (ที่ป้อนอินพุตภายนอก) เมื่อได้เกรเดียนต์เหล่านี้แล้ว การคำนวณเกรเดียนต์เทียบกับน้ำหนักของแต่ละโมดูลก็ทำได้ตรงไปตรงมา
โครงข่ายแบบป้อนไปข้างหน้า (Feedforward) และ ReLU
แอปพลิเคชันจำนวนมากใช้ สถาปัตยกรรม feedforward ที่เรียนรู้แมปอินพุตขนาดคงที่ (เช่น ภาพ) ไปสู่เอาต์พุตขนาดคงที่ (เช่น ความน่าจะเป็นของแต่ละหมวด) การไปจากชั้นหนึ่งสู่ชั้นถัดไป: หน่วย (units) ชุดหนึ่งคำนวณผลรวมถ่วงน้ำหนักของอินพุตจากชั้นก่อนหน้า แล้วส่งผ่านฟังก์ชันไม่เชิงเส้น
ปัจจุบันฟังก์ชันไม่เชิงเส้นที่นิยมที่สุดคือ Rectified Linear Unit (ReLU) ซึ่งเป็นเรกติไฟเออร์ครึ่งคลื่น f(z) = max(z, 0)
- อดีตใช้ฟังก์ชันที่เรียบกว่า เช่น tanh(z) หรือ logistic 1/(1+exp(−z))
- ReLU เรียนรู้ได้เร็วกว่ามาก ในโครงข่ายหลายชั้น และยอมให้ฝึกโครงข่าย supervised เชิงลึกได้ โดยไม่ต้อง pre-training แบบไม่มีผู้สอน
หน่วยที่ไม่ได้อยู่ในชั้นอินพุตหรือเอาต์พุตเรียกว่า หน่วยซ่อน (hidden units) ชั้นซ่อน (hidden layers) เปรียบเสมือนการ บิดเบือนอินพุตแบบไม่เชิงเส้น เพื่อให้หมวดต่าง ๆ แยกได้เชิงเส้น (linearly separable) ด้วยชั้นสุดท้าย (ดู Fig. 1)
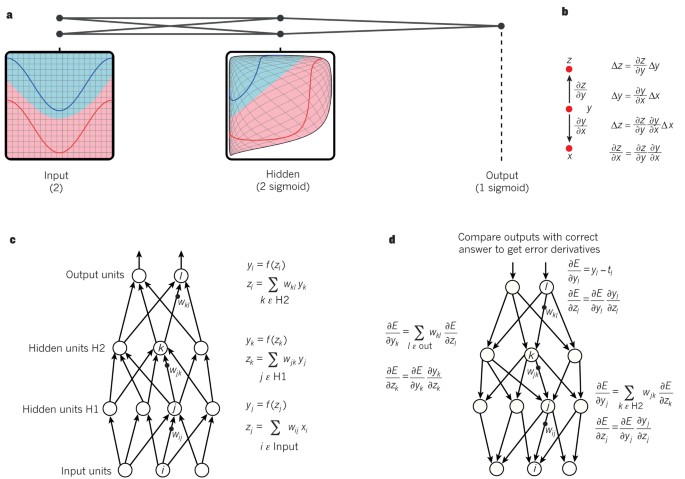
คำอธิบาย Figure 1 — โครงข่ายประสาทหลายชั้นและ Backpropagation:
- (a) โครงข่ายหลายชั้นสามารถ บิดเบือนปริภูมิอินพุต ให้คลาสของข้อมูล (เส้นแดง/น้ำเงิน) แยกได้เชิงเส้น (linearly separable) สังเกตว่ากริดปกติในปริภูมิอินพุต ถูกแปลงโดยหน่วยซ่อน ตัวอย่างนี้มี 2 หน่วยอินพุต 2 หน่วยซ่อน 1 หน่วยเอาต์พุต (โครงข่ายจริงมีหลายหมื่น–แสนหน่วย)
- (b) กฎลูกโซ่ของอนุพันธ์ (chain rule) บอกว่าผลเล็ก ๆ สองอย่างประกอบกันอย่างไร: การเปลี่ยน Δx ถูกแปลงเป็น Δy โดยคูณด้วย ∂y/∂x และ Δy สร้าง Δz → รวมกันได้ Δz = (∂z/∂y)(∂y/∂x)Δx (ใช้ได้กับเวกเตอร์ โดยอนุพันธ์เป็น เมทริกซ์จาโคเบียน)
- (c) สมการ forward pass ในโครงข่ายที่มี 2 ชั้นซ่อนและ 1 ชั้นเอาต์พุต แต่ละชั้นคำนวณอินพุตรวม z (ผลรวมถ่วงน้ำหนักของเอาต์พุตชั้นล่าง) แล้วใส่ฟังก์ชันไม่เชิงเส้น f(.) ฟังก์ชันที่ใช้รวม ReLU f(z)=max(0,z), tanh และ logistic f(z)=1/(1+exp(−z))
- (d) สมการ backward pass แต่ละชั้นซ่อนคำนวณอนุพันธ์ของ error เทียบกับเอาต์พุตของหน่วย (ผลรวมถ่วงน้ำหนักของอนุพันธ์ error เทียบกับอินพุตรวมของชั้นบน) แล้วแปลงเป็นอนุพันธ์เทียบกับอินพุตโดยคูณด้วยเกรเดียนต์ของ f(z) ที่ชั้นเอาต์พุต อนุพันธ์ของ error ได้จากการดิฟ cost function (ให้ yl−tl ถ้า cost = 0.5(yl−tl)²)
ปัญหา Local Minima ไม่ใช่ปัญหาจริง
ปลายทศวรรษ 1990 โครงข่ายประสาทและ backpropagation ถูกวงการ machine learning ทอดทิ้งเป็นส่วนใหญ่ เพราะเชื่อกันว่า gradient descent ธรรมดาจะ ติดอยู่ใน local minima ที่ไม่ดี (จุดที่ไม่มีการเปลี่ยนแปลงเล็ก ๆ ใดลด error เฉลี่ยได้)
แต่ในทางปฏิบัติ local minima ที่ไม่ดีแทบไม่เป็นปัญหากับโครงข่ายขนาดใหญ่ ไม่ว่าเงื่อนไขเริ่มต้นเป็นอย่างไร ระบบมักไปถึงคำตอบที่คุณภาพใกล้เคียงกัน ผลทางทฤษฎีและการทดลองชี้ว่า landscape เต็มไปด้วย จุดอาน (saddle points) จำนวนมหาศาล ที่เกรเดียนต์เป็นศูนย์ และพื้นผิวโค้งขึ้นในมิติส่วนใหญ่ โค้งลงในส่วนที่เหลือ จุดอานเหล่านี้เกือบทั้งหมดมีค่า objective function ใกล้เคียงกัน ดังนั้น ไม่สำคัญว่าอัลกอริทึมจะติดที่จุดอานไหน
การฟื้นคืนชีพราวปี 2006 (Pre-training)
ความสนใจใน deep feedforward network ฟื้นคืนราวปี 2006 โดยกลุ่มนักวิจัยที่รวมตัวกันโดย CIFAR (Canadian Institute for Advanced Research) พวกเขาเสนอ กระบวนการเรียนรู้แบบไม่มีผู้สอน (unsupervised learning) ที่สร้างชั้นของตัวตรวจจับคุณลักษณะได้โดย ไม่ต้องใช้ข้อมูลที่ติดป้าย
- เป้าหมายการเรียนรู้แต่ละชั้น = สามารถ สร้างใหม่ (reconstruct) หรือจำลองกิจกรรมของตัวตรวจจับ (หรืออินพุตดิบ) ในชั้นล่างได้
- การ “pre-training” หลายชั้นด้วยวัตถุประสงค์การสร้างใหม่ ช่วยตั้งค่าเริ่มต้นของน้ำหนักให้สมเหตุสมผล
- จากนั้นเพิ่มชั้นเอาต์พุตด้านบน แล้ว fine-tune ทั้งระบบด้วย backpropagation มาตรฐาน
วิธีนี้ได้ผลดีมากในการรู้จำเลขที่เขียนด้วยมือหรือตรวจจับคนเดินถนน โดยเฉพาะเมื่อข้อมูลติดป้ายมีจำกัดมาก
การประยุกต์ครั้งใหญ่ครั้งแรก: การรู้จำเสียงพูด
การประยุกต์ครั้งใหญ่ครั้งแรกของ pre-training คือ การรู้จำเสียงพูด เป็นไปได้เพราะ GPU ที่เร็วและเขียนโปรแกรมง่าย ทำให้ฝึกได้เร็วขึ้น 10–20 เท่า ในปี 2009 ใช้แมปหน้าต่างเวลาสั้น ๆ ของสัมประสิทธิ์จากคลื่นเสียง ไปสู่ความน่าจะเป็นของชิ้นส่วนเสียงพูด ทำลายสถิติบนเบนช์มาร์กคำศัพท์เล็ก และพัฒนาต่อสู่งานคำศัพท์ใหญ่ ภายในปี 2012 เวอร์ชันต่าง ๆ ถูกนำไปใช้ในโทรศัพท์ Android แล้ว
สำหรับชุดข้อมูลเล็ก unsupervised pre-training ช่วย ป้องกัน overfitting และวางนัยทั่วไปได้ดีขึ้น โดยเฉพาะใน transfer setting (มีตัวอย่างมากในงานต้นทาง แต่น้อยในงานปลายทาง) แต่เมื่อ deep learning ฟื้นแล้ว ปรากฏว่า pre-training จำเป็นเฉพาะชุดข้อมูลเล็กเท่านั้น
มีโครงข่าย feedforward ชนิดหนึ่งที่ฝึกง่ายและวางนัยทั่วไปได้ดีกว่าโครงข่ายที่เชื่อมต่อเต็มระหว่างชั้น นั่นคือ โครงข่ายประสาทคอนโวลูชัน (Convolutional Neural Network — ConvNet)
โครงข่ายประสาทคอนโวลูชัน (Convolutional Neural Networks)
ConvNets ออกแบบมาเพื่อประมวลผลข้อมูลที่อยู่ในรูป อาเรย์หลายชุด (multiple arrays) เช่น ภาพสีประกอบด้วยอาเรย์ 2 มิติ 3 ชุด (ความเข้มพิกเซลใน 3 ช่องสี) ลักษณะข้อมูลหลายแบบเป็นอาเรย์หลายชุด:
- 1D สำหรับสัญญาณและลำดับ รวมถึงภาษา
- 2D สำหรับภาพหรือสเปกโตรแกรมเสียง
- 3D สำหรับวิดีโอหรือภาพเชิงปริมาตร
4 แนวคิดหลักของ ConvNets
- การเชื่อมต่อเฉพาะถิ่น (local connections)
- น้ำหนักร่วมกัน (shared weights)
- การพูล (pooling)
- การใช้หลายชั้น (use of many layers)
สถาปัตยกรรม: Convolutional Layer + Pooling Layer
สถาปัตยกรรม ConvNet ทั่วไป (ดู Fig. 2) จัดเป็น ชุดของสเตจ (stages) สเตจแรก ๆ ประกอบด้วยสองชนิด: ชั้นคอนโวลูชัน (convolutional layers) และ ชั้นพูลลิง (pooling layers)

คำอธิบาย Figure 2 — ภายในโครงข่ายคอนโวลูชัน: แสดง เอาต์พุต (ไม่ใช่ฟิลเตอร์) ของแต่ละชั้นใน ConvNet ทั่วไปที่ใช้กับภาพหมา Samoyed (อินพุต RGB) แต่ละภาพสี่เหลี่ยมคือ feature map ของคุณลักษณะที่เรียนรู้หนึ่งตัว ตรวจจับ ณ ทุกตำแหน่งภาพ ข้อมูลไหล จากล่างขึ้นบน โดยคุณลักษณะระดับล่างทำหน้าที่เป็นตัวตรวจจับขอบมีทิศทาง (oriented edge detectors) แล้วคำนวณคะแนนสำหรับแต่ละคลาสภาพในเอาต์พุต ผ่านการสลับ Convolutions + ReLU และ Max pooling
Convolutional layer:
- หน่วยจัดเป็น แผนที่คุณลักษณะ (feature maps) ภายในแต่ละแผนที่ หน่วยเชื่อมต่อกับ แพตช์เฉพาะถิ่น (local patches) ในแผนที่ของชั้นก่อนหน้า ผ่านชุดน้ำหนักที่เรียกว่า ฟิลเตอร์แบงก์ (filter bank)
- ผลรวมถ่วงน้ำหนักเฉพาะถิ่นถูกส่งผ่านฟังก์ชันไม่เชิงเส้น เช่น ReLU
- ทุกหน่วยในแผนที่เดียวกันใช้ filter bank เดียวกัน (shared weights) ส่วนแผนที่ต่างกันใช้ filter bank ต่างกัน
เหตุผลของสถาปัตยกรรมนี้ 2 ข้อ:
- ในข้อมูลอาเรย์อย่างภาพ กลุ่มค่าเฉพาะถิ่นมัก สหสัมพันธ์กันสูง (highly correlated) ก่อเป็น motif เฉพาะถิ่นที่ตรวจจับง่าย
- สถิติเฉพาะถิ่นของภาพ ไม่แปรผันตามตำแหน่ง (invariant to location) — ถ้า motif ปรากฏที่จุดหนึ่งได้ ก็ปรากฏที่ใดก็ได้ จึงให้หน่วยต่างตำแหน่ง ใช้น้ำหนักร่วมกัน และตรวจจับรูปแบบเดียวกันในส่วนต่าง ๆ ของอาเรย์ (ในเชิงคณิตศาสตร์ การกรองที่ feature map ทำคือ คอนโวลูชันไม่ต่อเนื่อง (discrete convolution) จึงเป็นที่มาของชื่อ)
Pooling layer:
- บทบาทของชั้นพูลคือ รวมคุณลักษณะที่คล้ายกันเชิงความหมาย (semantically similar features) ให้เป็นหนึ่งเดียว
- เพราะตำแหน่งสัมพัทธ์ของคุณลักษณะใน motif แปรผันได้บ้าง การตรวจจับ motif อย่างเชื่อถือได้ทำได้ด้วยการ ลดความละเอียดตำแหน่ง (coarse-graining)
- หน่วยพูลทั่วไปคำนวณ ค่าสูงสุด (maximum) ของแพตช์เฉพาะถิ่น (max pooling) หน่วยพูลข้างเคียงรับอินพุตจากแพตช์ที่เลื่อนมากกว่าหนึ่งแถว/คอลัมน์ จึง ลดมิติของการแทนค่า และสร้าง ความไม่แปรผันต่อการเลื่อนและการบิดเบือนเล็กน้อย
สเตจของคอนโวลูชัน + ไม่เชิงเส้น + พูลลิง 2–3 สเตจถูกซ้อนกัน ตามด้วยชั้นคอนโวลูชันและชั้นเชื่อมต่อเต็ม (fully-connected) เพิ่มเติม การ backpropagate เกรเดียนต์ผ่าน ConvNet ง่ายพอ ๆ กับโครงข่ายเชิงลึกทั่วไป จึงฝึกน้ำหนักทั้งหมดใน filter bank ได้
ลำดับชั้นเชิงประกอบ (Compositional Hierarchies)
โครงข่ายเชิงลึกใช้ประโยชน์จากคุณสมบัติที่ว่าสัญญาณธรรมชาติจำนวนมากเป็น ลำดับชั้นเชิงประกอบ (compositional hierarchies) — คุณลักษณะระดับสูงได้จากการประกอบคุณลักษณะระดับล่าง
- ในภาพ: ขอบ → motifs → ส่วน (parts) → วัตถุ (objects)
- ในเสียง/ข้อความ: เสียง → phones → phonemes → พยางค์ → คำ → ประโยค
การพูลช่วยให้การแทนค่าเปลี่ยนน้อยมาก เมื่อองค์ประกอบในชั้นก่อนหน้าเปลี่ยนตำแหน่งและรูปลักษณ์
แรงบันดาลใจจากประสาทวิทยา
ชั้นคอนโวลูชันและพูลลิงได้แรงบันดาลใจโดยตรงจากแนวคิดคลาสสิกเรื่อง simple cells และ complex cells ในประสาทวิทยาการมองเห็น และสถาปัตยกรรมโดยรวมชวนให้นึกถึงลำดับชั้น LGN–V1–V2–V4–IT ในวิถีท้อง (ventral pathway) ของคอร์เทกซ์การมองเห็น เมื่อแสดงภาพเดียวกันแก่ ConvNet และลิง กิจกรรมของหน่วยระดับสูงใน ConvNet อธิบายความแปรปรวนได้ครึ่งหนึ่งของเซลล์ประสาท 160 ตัวในคอร์เทกซ์ inferotemporal ของลิง ConvNets มีรากจาก neocognitron (สถาปัตยกรรมคล้ายกันแต่ไม่มีอัลกอริทึม supervised แบบ end-to-end อย่าง backpropagation)
ประวัติการใช้งาน
มีการประยุกต์ ConvNet ย้อนไปถึงต้นทศวรรษ 1990 เริ่มจาก time-delay neural networks สำหรับการรู้จำเสียงพูดและการอ่านเอกสาร — ปลายทศวรรษ 1990 ระบบนี้อ่าน เช็คมากกว่า 10% ของเช็คทั้งหมดในสหรัฐฯ ต่อมา Microsoft นำระบบ OCR/การรู้จำลายมือที่ใช้ ConvNet ไปใช้งาน รวมถึงทดลองตรวจจับวัตถุ ใบหน้า มือ ในภาพธรรมชาติ
ความเข้าใจภาพด้วยโครงข่ายคอนโวลูชันเชิงลึก
ตั้งแต่ต้นทศวรรษ 2000 ConvNets ถูกใช้อย่างประสบความสำเร็จในงาน ตรวจจับ (detection), แบ่งส่วน (segmentation) และรู้จำ (recognition) วัตถุและภูมิภาคในภาพ ซึ่งล้วนเป็นงานที่ข้อมูลติดป้ายค่อนข้างมาก เช่น การรู้จำป้ายจราจร, การแบ่งส่วนภาพชีวภาพ (โดยเฉพาะ connectomics), การตรวจจับใบหน้า ข้อความ คนเดินถนน ความสำเร็จเชิงปฏิบัติที่สำคัญล่าสุดคือ การรู้จำใบหน้า (face recognition)
ภาพสามารถติดป้ายที่ ระดับพิกเซล (pixel level) ได้ ซึ่งจะมีประโยชน์ในเทคโนโลยี เช่น หุ่นยนต์เคลื่อนที่อัตโนมัติ (autonomous mobile robots) และ รถยนต์ขับเคลื่อนเอง (self-driving cars) บริษัทอย่าง Mobileye และ NVIDIA ใช้วิธีฐาน ConvNet ในระบบการมองเห็นของรถ
จุดเปลี่ยน: ImageNet 2012
แม้ประสบความสำเร็จ แต่ ConvNets ถูกวงการ computer vision และ machine learning กระแสหลักทอดทิ้งเป็นส่วนใหญ่ จนถึง การแข่งขัน ImageNet ปี 2012 เมื่อนำ deep ConvNet ไปใช้กับชุดข้อมูลภาพราว 1 ล้านภาพ จากเว็บ ที่มี 1,000 คลาส มันได้ผลลัพธ์น่าทึ่ง ลดอัตราความผิดพลาดลงเกือบครึ่ง เมื่อเทียบกับวิธีคู่แข่งที่ดีที่สุด
ความสำเร็จนี้มาจาก:
- การใช้ GPU อย่างมีประสิทธิภาพ
- ReLUs
- เทคนิคเรกูลาไรเซชันใหม่ชื่อ dropout
- เทคนิคสร้างตัวอย่างฝึกเพิ่มด้วยการบิดภาพเดิม (data augmentation)
ความสำเร็จนี้ก่อให้เกิด การปฏิวัติในวงการ computer vision ปัจจุบัน ConvNets เป็นวิธีหลักในเกือบทุกงานรู้จำและตรวจจับ และเข้าใกล้ประสิทธิภาพมนุษย์ในบางงาน การสาธิตที่น่าตื่นเต้นล่าสุดผสาน ConvNets กับ RNN เพื่อ สร้างคำบรรยายภาพ (image captions) (ดู Fig. 3)
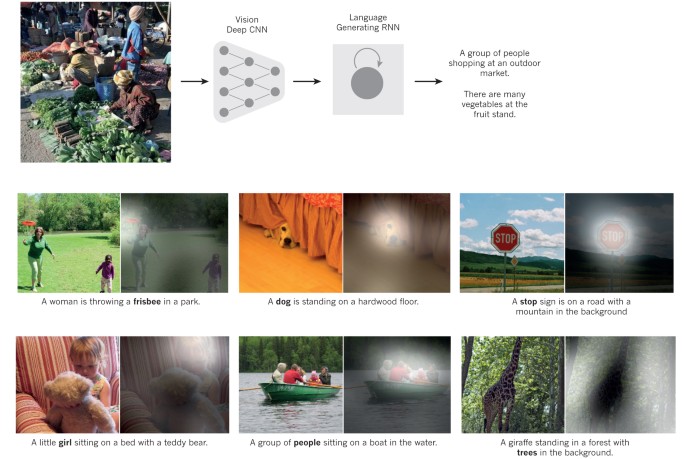
คำอธิบาย Figure 3 — จากภาพสู่ข้อความ (Image to Text): คำบรรยายภาพที่สร้างโดย RNN ซึ่งรับเป็นอินพุตเสริมคือการแทนค่าที่สกัดโดย deep CNN จากภาพทดสอบ โดย RNN ถูกฝึกให้ “แปล” การแทนค่าระดับสูงของภาพเป็นคำบรรยาย เมื่อให้ RNN มีความสามารถ โฟกัสความสนใจ (attention) ไปยังตำแหน่งต่าง ๆ ในภาพ (แพตช์ที่สว่างกว่าได้รับความสนใจมากกว่า) ขณะสร้างแต่ละคำ พบว่ามันใช้ความสามารถนี้ “แปล” ภาพเป็นคำบรรยายได้ดีขึ้น
ฮาร์ดแวร์และอุตสาหกรรม
สถาปัตยกรรม ConvNet ล่าสุดมี 10–20 ชั้นของ ReLU, น้ำหนักหลายร้อยล้านตัว และการเชื่อมต่อหลายพันล้าน เมื่อสองปีก่อนการฝึกอาจใช้เวลาหลายสัปดาห์ แต่ความก้าวหน้าด้านฮาร์ดแวร์ ซอฟต์แวร์ และการขนานอัลกอริทึม (parallelization) ลดเวลาฝึกเหลือไม่กี่ชั่วโมง บริษัทเทคโนโลยีใหญ่ (Google, Facebook, Microsoft, IBM, Yahoo!, Twitter, Adobe) และสตาร์ตอัปจำนวนมากนำไปใช้ และบริษัท NVIDIA, Mobileye, Intel, Qualcomm, Samsung กำลังพัฒนา ชิป ConvNet เพื่องานวิชันเรียลไทม์ในสมาร์ตโฟน กล้อง หุ่นยนต์ และรถขับเคลื่อนเอง
การแทนค่าแบบกระจายและการประมวลผลภาษา
ทฤษฎี deep learning แสดงว่าโครงข่ายเชิงลึกมี ข้อได้เปรียบเชิงเลขชี้กำลัง (exponential advantages) 2 แบบ เหนืออัลกอริทึมคลาสสิกที่ไม่ใช้ การแทนค่าแบบกระจาย (distributed representations) ทั้งสองเกิดจากพลังของการประกอบ (composition):
- Distributed representations ช่วยวางนัยทั่วไปไปยังการรวมกันใหม่ของค่าคุณลักษณะที่เรียนรู้ ที่เกินกว่าที่เห็นตอนฝึก (เช่น คุณลักษณะไบนารี n ตัว ให้ 2ⁿ การรวมกัน)
- การประกอบชั้นของการแทนค่า (composing layers) ในโครงข่ายเชิงลึก ให้ข้อได้เปรียบเลขชี้กำลังอีกแบบ (เลขชี้กำลังในความลึก/depth)
เวกเตอร์คำ (Word Vectors)
ชั้นซ่อนของโครงข่ายหลายชั้นเรียนรู้แทนค่าอินพุตในแบบที่ทำนายเอาต์พุตเป้าหมายได้ง่าย แสดงให้เห็นชัดด้วยการฝึกโครงข่ายให้ ทำนายคำถัดไป (next word) จากบริบทของคำก่อนหน้า แต่ละคำในบริบทถูกป้อนเป็น เวกเตอร์ one-of-N (องค์ประกอบหนึ่งมีค่า 1 ที่เหลือเป็น 0)
ในชั้นแรก แต่ละคำสร้างรูปแบบการกระตุ้นต่างกัน เรียกว่า เวกเตอร์คำ (word vectors) ในแบบจำลองภาษา ชั้นอื่นเรียนรู้แปลงเวกเตอร์คำอินพุตเป็นเวกเตอร์คำเอาต์พุตของคำถัดไปที่ทำนาย โครงข่ายเรียนรู้เวกเตอร์คำที่มีองค์ประกอบแอ็กทีฟหลายตัว ซึ่งแต่ละตัวตีความได้เป็นคุณลักษณะแยกของคำ — คุณลักษณะเชิงความหมายเหล่านี้ ไม่ได้ปรากฏชัดในอินพุต แต่ถูกค้นพบโดยกระบวนการเรียนรู้ ในฐานะวิธีแยกตัวประกอบความสัมพันธ์เชิงโครงสร้างเป็น “กฎย่อย (micro-rules)” หลายตัว
เวกเตอร์คำเหล่านี้ประกอบด้วยคุณลักษณะที่เรียนรู้ ไม่ได้ถูกกำหนดล่วงหน้าโดยผู้เชี่ยวชาญ แต่ค้นพบอัตโนมัติโดยโครงข่าย ปัจจุบันใช้กันแพร่หลายมากในงาน NLP (ดู Fig. 4)
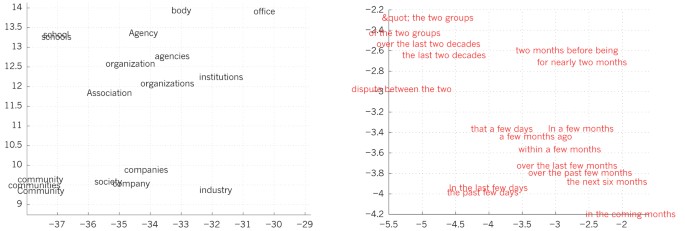
คำอธิบาย Figure 4 — การมองเห็นเวกเตอร์คำที่เรียนรู้:
- ซ้าย: การแทนค่าคำที่เรียนรู้สำหรับโมเดลภาษา ฉายลงสู่ 2 มิติด้วยอัลกอริทึม t-SNE เพื่อแสดงผล
- ขวา: การแทนค่า 2 มิติของวลีที่เรียนรู้โดย encoder–decoder RNN อังกฤษ→ฝรั่งเศส
สังเกตว่าคำหรือลำดับคำที่ คล้ายกันเชิงความหมาย ถูกแมปไปยังการแทนค่าที่อยู่ใกล้กัน distributed representations ได้มาจาก backpropagation ที่เรียนรู้ทั้งการแทนค่าของแต่ละคำและฟังก์ชันทำนายปริมาณเป้าหมายไปพร้อมกัน
ตรรกะ vs. โครงข่ายประสาท
ประเด็นเรื่องการแทนค่าอยู่ใจกลางการถกเถียงระหว่างกระบวนทัศน์ แรงบันดาลใจจากตรรกะ (logic-inspired) กับ แรงบันดาลใจจากโครงข่ายประสาท (neural-network-inspired):
- Logic-inspired: สัญลักษณ์ (symbol) มีคุณสมบัติเดียวคือเหมือนหรือไม่เหมือนสัญลักษณ์อื่น ไม่มีโครงสร้างภายในที่เกี่ยวข้อง การให้เหตุผลต้องผูกสัญลักษณ์กับตัวแปรในกฎอนุมานที่เลือกอย่างพิถีพิถัน
- Neural network: ใช้ เวกเตอร์กิจกรรมขนาดใหญ่ (big activity vectors), เมทริกซ์น้ำหนักขนาดใหญ่ และฟังก์ชันไม่เชิงเส้นสเกลาร์ เพื่อทำการอนุมานแบบ “สัญชาตญาณ (intuitive)” ที่รวดเร็ว ซึ่งหนุนการให้เหตุผลสามัญสำนึก
N-grams vs. แบบจำลองภาษาเชิงประสาท
ก่อนมีแบบจำลองภาษาเชิงประสาท วิธีมาตรฐานคือ นับความถี่ลำดับสัญลักษณ์สั้น ๆ ยาวถึง N (N-grams) จำนวน N-grams ที่เป็นไปได้อยู่ในอันดับ Vᴺ (V = ขนาดคลังคำ) จึงต้องใช้คลังฝึกขนาดใหญ่มากหากพิจารณาบริบทยาว N-grams ปฏิบัติต่อแต่ละคำเป็น หน่วยอะตอม (atomic unit) จึง วางนัยทั่วไปข้ามลำดับคำที่สัมพันธ์กันเชิงความหมายไม่ได้ ขณะที่แบบจำลองภาษาเชิงประสาททำได้ เพราะเชื่อมแต่ละคำกับเวกเตอร์คุณลักษณะจำนวนจริง และคำที่สัมพันธ์กันเชิงความหมายจะอยู่ใกล้กันในปริภูมิเวกเตอร์
โครงข่ายประสาทเวียนซ้ำ (Recurrent Neural Networks)
เมื่อ backpropagation เพิ่งถูกนำเสนอ การใช้งานที่น่าตื่นเต้นที่สุดคือฝึก โครงข่ายประสาทเวียนซ้ำ (RNNs) สำหรับงานที่มีอินพุตเชิงลำดับ เช่น เสียงพูดและภาษา มักดีกว่าที่จะใช้ RNN
กลไกการทำงาน
RNNs ประมวลผลลำดับอินพุต ทีละองค์ประกอบ โดยรักษา เวกเตอร์สถานะ (state vector) ไว้ในหน่วยซ่อน ซึ่งบรรจุข้อมูลเกี่ยวกับ ประวัติขององค์ประกอบในอดีตทั้งหมด ของลำดับโดยปริยาย เมื่อเรามองเอาต์พุตของหน่วยซ่อน ณ ขั้นเวลา (time step) ที่ไม่ต่อเนื่องต่าง ๆ ราวกับเป็นเอาต์พุตของเซลล์ประสาทคนละตัวในโครงข่ายหลายชั้นเชิงลึก (ดู Fig. 5) ก็จะเห็นชัดว่าเรา ใช้ backpropagation ฝึก RNN ได้อย่างไร
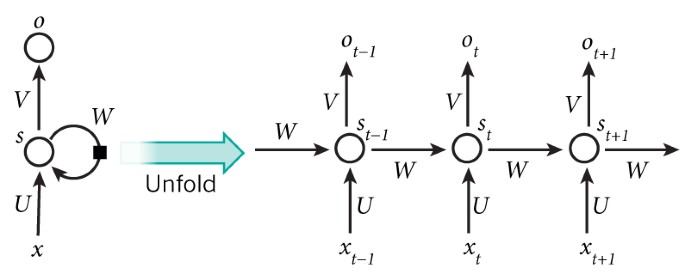
คำอธิบาย Figure 5 — RNN และการคลี่ตามเวลา (Unfolding in Time): เซลล์ประสาทเทียม (หน่วยซ่อนรวมกันที่โหนด s ค่า sₜ ณ เวลา t) รับอินพุตจากเซลล์ที่ขั้นเวลาก่อนหน้า (สี่เหลี่ยมดำ = หน่วงหนึ่งขั้นเวลา) RNN แมปลำดับอินพุต xₜ เป็นลำดับเอาต์พุต oₜ โดยแต่ละ oₜ ขึ้นกับ xₜ′ ก่อนหน้าทั้งหมด (t′ ≤ t) พารามิเตอร์ชุดเดียวกัน (เมทริกซ์ U, V, W) ถูกใช้ทุกขั้นเวลา อัลกอริทึม backpropagation ใช้กับกราฟการคำนวณของโครงข่ายที่คลี่แล้วได้โดยตรง เพื่อคำนวณอนุพันธ์ของ error รวมเทียบกับทุกสถานะ sₜ และทุกพารามิเตอร์
ปัญหา Exploding / Vanishing Gradients
RNNs เป็นระบบพลวัตที่ทรงพลังมาก แต่ฝึกยาก เพราะเกรเดียนต์ที่แพร่ย้อนกลับ เติบโตหรือหดตัว ในแต่ละขั้นเวลา ดังนั้นเมื่อผ่านหลายขั้นเวลา มักจะ ระเบิด (explode) หรือ หายไป (vanish)
การประยุกต์: การแปลภาษาด้วยเครื่อง
ด้วยความก้าวหน้าด้านสถาปัตยกรรมและวิธีฝึก RNNs เก่งมากในการทำนายอักขระหรือคำถัดไป และใช้กับงานซับซ้อนได้ ตัวอย่างการแปลภาษา:
- อ่านประโยคภาษาอังกฤษทีละคำด้วยโครงข่าย “ตัวเข้ารหัส (encoder)” ภาษาอังกฤษ
- เวกเตอร์สถานะสุดท้ายของหน่วยซ่อนเป็นตัวแทนที่ดีของ “ความคิด (thought)” ที่ประโยคสื่อ — เรียก thought vector
- ใช้ thought vector เป็นสถานะซ่อนเริ่มต้นของโครงข่าย “ตัวถอดรหัส (decoder)” ภาษาฝรั่งเศส
- decoder ให้การแจกแจงความน่าจะเป็นของคำแรกในคำแปลฝรั่งเศส เลือกคำ แล้วป้อนกลับเป็นอินพุตเพื่อทำนายคำถัดไป ทำซ้ำจนเจอจุดจบประโยค
วิธีที่ดูเรียบง่ายนี้ แข่งขันได้กับเทคโนโลยีล้ำสมัยอย่างรวดเร็ว และทำให้เกิดข้อสงสัยจริงจังว่า การเข้าใจประโยคต้องอาศัยนิพจน์เชิงสัญลักษณ์ภายในแบบที่จัดการด้วยกฎอนุมานหรือไม่ มันสอดคล้องมากกว่ากับมุมมองว่าการให้เหตุผลในชีวิตประจำวันเกี่ยวข้องกับ การเปรียบเทียบ (analogies) หลายอย่างพร้อมกัน
นอกจากแปลความหมายของประโยคฝรั่งเศสเป็นอังกฤษ ยังเรียนรู้ “แปล” ความหมายของภาพเป็นประโยคอังกฤษ ได้ (image captioning) — encoder เป็น deep ConvNet ที่แปลงพิกเซลเป็นเวกเตอร์กิจกรรม ส่วน decoder เป็น RNN คล้ายที่ใช้แปลภาษา
Long Short-Term Memory (LSTM)
RNNs เมื่อ คลี่ตามเวลา (unfolded in time) มองได้เป็นโครงข่าย feedforward ที่ลึกมาก ซึ่งทุกชั้น ใช้น้ำหนักร่วมกัน แม้จุดประสงค์หลักคือเรียนรู้ การพึ่งพาระยะยาว (long-term dependencies) แต่หลักฐานชี้ว่า ยากที่จะเรียนรู้เก็บข้อมูลไว้นานมาก
เพื่อแก้ปัญหานี้ แนวคิดหนึ่งคือ เสริมโครงข่ายด้วยหน่วยความจำชัดแจ้ง (explicit memory) ข้อเสนอแรกคือ เครือข่าย Long Short-Term Memory (LSTM) ที่ใช้หน่วยซ่อนพิเศษซึ่งโดยธรรมชาติจะจดจำอินพุตได้นาน:
- หน่วยพิเศษเรียกว่า เซลล์ความจำ (memory cell) ทำหน้าที่เหมือนตัวสะสม (accumulator) หรือเซลล์ประสาทรั่วแบบมีประตู (gated leaky neuron)
- มีการเชื่อมต่อกับตัวเองที่ขั้นเวลาถัดไปด้วย น้ำหนักเท่ากับหนึ่ง จึงคัดลอกสถานะของตัวเองและสะสมสัญญาณภายนอก
- การเชื่อมต่อตัวเองนี้ถูก ควบคุมแบบคูณ (multiplicatively gated) โดยอีกหน่วยที่เรียนรู้ตัดสินใจว่าเมื่อใดควรล้างเนื้อหาความจำ
LSTM พิสูจน์แล้วว่ามีประสิทธิภาพกว่า RNN ทั่วไป โดยเฉพาะเมื่อมีหลายชั้นต่อขั้นเวลา ช่วยให้ระบบรู้จำเสียงพูดทำงานครบวงจรจากเสียงสู่ลำดับอักขระ ปัจจุบัน LSTM หรือหน่วยมีประตู (gated units) ถูกใช้ใน encoder/decoder ที่ทำงานได้ดีในการแปลภาษา
หน่วยความจำเสริม (Memory Networks / Neural Turing Machines)
มีข้อเสนอเสริม RNN ด้วยโมดูลความจำหลายแบบ:
- Neural Turing Machine: โครงข่ายถูกเสริมด้วยความจำแบบ “เทป (tape-like)” ที่ RNN เลือกอ่าน/เขียนได้ — สอน “อัลกอริทึม” ได้ เช่น เรียงลำดับสัญลักษณ์ตามค่าความสำคัญ
- Memory networks: โครงข่ายปกติเสริมด้วยความจำเชิงเชื่อมโยง (associative memory) — ทำผลงานเยี่ยมบนเบนช์มาร์กการตอบคำถาม ใช้จดจำเรื่องราวที่จะถูกถามภายหลัง
อนาคตของ Deep Learning
Unsupervised Learning จะสำคัญขึ้น
Unsupervised learning มีบทบาทเป็นตัวเร่งในการฟื้นความสนใจ deep learning แต่ภายหลังถูกบดบังด้วยความสำเร็จของ supervised learning ล้วน ๆ ผู้เขียนคาดว่า unsupervised learning จะ สำคัญมากขึ้นในระยะยาว เพราะการเรียนรู้ของมนุษย์และสัตว์ส่วนใหญ่เป็นแบบไม่มีผู้สอน — เราค้นพบโครงสร้างของโลกโดยการสังเกต ไม่ใช่ถูกบอกชื่อของทุกวัตถุ
การมองเห็นแบบแอ็กทีฟ + Reinforcement Learning
การมองเห็นของมนุษย์เป็น กระบวนการแอ็กทีฟ ที่สุ่มตัวอย่างลานแสง (optic array) ตามลำดับอย่างชาญฉลาดเฉพาะงาน โดยใช้ fovea ความละเอียดสูงเล็ก ๆ ล้อมด้วยบริเวณรอบความละเอียดต่ำ ผู้เขียนคาดว่าความก้าวหน้าด้านวิชันจะมาจากระบบที่ฝึกแบบ end-to-end ผสาน ConvNets กับ RNNs ที่ใช้ reinforcement learning เพื่อตัดสินใจว่าจะมองที่ใด ระบบที่ผสาน deep learning กับ reinforcement learning ยังอยู่ในช่วงเริ่มต้น แต่ก็เอาชนะระบบวิชันแบบพาสซีฟในงานจำแนกแล้ว และเรียนรู้เล่นวิดีโอเกมหลายเกมได้น่าประทับใจ
NLU และการให้เหตุผล
ความเข้าใจภาษาธรรมชาติ (NLU) เป็นอีกพื้นที่ที่ deep learning จะมีผลกระทบใหญ่ ระบบที่ใช้ RNN เข้าใจประโยคหรือทั้งเอกสารจะดีขึ้นมากเมื่อเรียนรู้ กลยุทธ์การให้ความสนใจแบบเลือกเฟ้น (selective attention) ทีละส่วน
ท้ายที่สุด ความก้าวหน้าครั้งใหญ่ใน AI จะมาจากระบบที่ ผสานการเรียนรู้การแทนค่า (representation learning) เข้ากับการให้เหตุผลซับซ้อน (complex reasoning) แม้ deep learning และการให้เหตุผลแบบง่ายถูกใช้ในการรู้จำเสียง/ลายมือมานาน แต่ต้องการกระบวนทัศน์ใหม่มาแทนที่การจัดการนิพจน์เชิงสัญลักษณ์แบบใช้กฎ ด้วย การดำเนินการบนเวกเตอร์ขนาดใหญ่ (operations on large vectors)
| ศัพท์ | ความหมายย่อ |
|---|---|
| Representation learning | ป้อนข้อมูลดิบ แล้วเครื่องค้นพบ representation เอง |
| Backpropagation | ใช้ chain rule แพร่เกรเดียนต์ย้อนกลับเพื่ออัปเดตน้ำหนัก |
| SGD | ปรับน้ำหนักด้วยเกรเดียนต์เฉลี่ยจากตัวอย่างชุดเล็กแบบสุ่ม |
| ReLU | f(z)=max(0,z) — เรียนรู้เร็วในโครงข่ายลึก |
| ConvNet | local connections + shared weights + pooling + many layers (เด่นด้านภาพ) |
| Pooling (max) | รวมคุณลักษณะคล้ายกัน ลดมิติ สร้าง invariance ต่อการเลื่อน |
| Distributed representation | คุณลักษณะไม่แยกขาดกัน — n ไบนารี ให้ 2ⁿ การรวมกัน |
| RNN | ประมวลลำดับทีละองค์ประกอบ เก็บ state vector |
| Vanishing/Exploding gradient | ปัญหาเกรเดียนต์หด/ระเบิดเมื่อผ่านหลายขั้นเวลาใน RNN |
| LSTM | RNN + memory cell ควบคุมด้วย gate — จำระยะยาวได้ |
| Saddle point | จุดเกรเดียนต์ศูนย์ที่พบมากในโครงข่ายใหญ่ (ไม่ใช่ local minima) |
ที่มา: LeCun, Y., Bengio, Y. & Hinton, G. “Deep learning.” Nature 521, 436–444 (2015). คำแปลและสรุปนี้จัดทำเพื่อการอ่านทบทวนและอ้างอิงเท่านั้น